Architecture
So How is TextPipe Different?
Traditional text transformation software has a number of limitations:
- They rely on loading the entire file into memory and then operating on it. This works well for small files, but for files over 5 MB it is extremely slow, and impossible for large files
- They can perform only one transformation at a time e.g. you must perform a single search and replace across your entire website, wait for it to complete, then setup a second search and replace, wait, etc. This isn't practical for more than 1000 files, especially if you have many transformations to perform
- They can't restrict where a transformation occurs, for example, to a range of lines, or just in a specific CSV or tab-delimited field
- They can't perform custom processing. Text manipulation always has custom requirements that can only be met by custom code.
The TextPipe Architecture
You may be familiar with the concept of 'pipes' from Unix or DOS (don't worry if you haven't).
c:\> dir | sort | head | more
This concept allows one program to run, and for its output to be fed into the next program as its input. In the example above, we perform a dir, getting a directory listing, which is then fed into sort, to sort the output, which is then fed into head, which gives us the first 20 lines, which is then fed into more, to allow us to scroll through the list.
TextPipe architecture is very similar to this.
Each file is broken up into small pieces, which are progressively fed through a series of filters. Each filter performs a simple piece of text manipulation, like a search and replace, converting to UPPERCASE, removing HTML etc. When the filter is finished with its piece, it feeds it into the next filter, and finally, the output file.
This architecture allows TextPipe to work with files or streams of unlimited size, and perform an unlimited number of operations on each file, without using temporary disk space (except for sorting).
Sub Filtering
Normally all the input is processed by every filter as it moves sequentially from input to output. TextPipe introduces a new text processing concept called sub filtering (also referred to as filter cascades, or 2-dimensional text processing).
A TextPipe restriction filter (found in the Restrict Menu) allows sub sections of the text to be operated on independently of the main text. Let's look at an example:
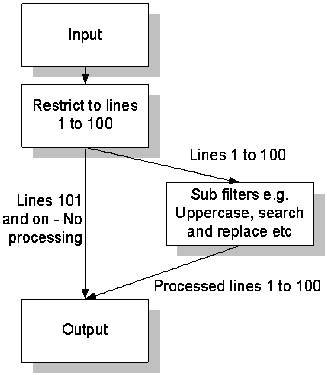
| Flowchart representation | Looks like this in TextPipe: |
 |
 |
Click here to receive our document TextPipe Restrictions - What are they and how do I use them?.
In the example above, a restriction filter passes lines 1 to 100 of the main text to the sub filter, which can be any combination of filters, such as a Convert to Uppercase filter, a Database filter, a Search and Replace filter, or another restriction. The processed text then rejoins the main text. The net effect is that the filter constrains or limits the effect of the sub filters to just lines 1 to 100, all other lines are unaffected.
Here's another example.
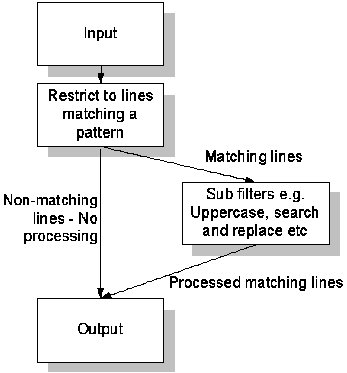
| Flowchart representation | Looks like this in TextPipe: |
 |
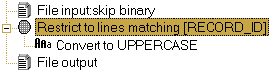 |
In the example above, a filter restricts lines from the main text to those matching a pattern. These matching lines get passed to the sub filter, which can be any combination of filters, a VBScript filter, a Search and Replace filter, an Output to File filter etc. The processed text then rejoins the main text. The net effect here is that the restriction filter limits the effect of the sub filters to just lines matching a pattern, all other lines are unaffected.
A Restrict Lines filter can be combined with a Restrict Columns filters to sub filter a rectangular block of text, for example, Searching and Replacing just inside a block of text. We also have filters to restrict CSV fields, restrict Tab-delimited fields, restrict blocks of a specified record length, and restrict matching and non-matching lines. All these restriction filters can be combined together with any number of sub filters.
The Search and Replace filter is a special kind of restriction filter. It allows sub filters to operate on the replacement text, which can be used in a number of ways:
- Change the case of the replacement text (e.g. Convert to Uppercase)
- You can use a second Search and Replace filter as a sub filter to only search and replace inside the replacement. This is very handy for HTML web pages and XML, because you can use a search and replace to match, say, image tags, then a second search and replace inside it to match the WIDTH setting. This ensures you only alter the WIDTH of images, not of any other tag. TextPipe includes a Find Inside HTML dialog to build these kinds of filters.
Unmatched Power and Flexibility
TextPipe provides an array of over 100 inbuilt filters that is unmatched by any other processing tool. We have filters for extracting data from databases, extracting text from web pages and mainframe reports for data mining, and a scripting filter where you can code your own filter in VBScript, JScript or a range of other scripting languages.
Other Performance Enhancements
TextPipe takes advantage of a variety of other performance enhancements:
- Windows sequential stream processing API to enhance text stream processing
- Fibonacci buffering to reduce memory allocation/reallocation overhead
- Boyer-Moore-* searching
- and more...
Parallel SMP Processor Arrays
With an appropriate market need, TextPipe can support parallel SMP processor arrays performing huge quantities of text processing. One such market need might include search engine document preparation.
If you have any questions, please contact us.