Convert EBCDIC files to ASCII - TextPipe Pro
EBCDIC to ASCII, and ASCII to EBCDIC converter tool
TextPipe Pro is a robust EBCDIC to ASCII conversion utility. Once your files are decoded from EBCDIC into an ASCII text file in CSV, Tab, XML, JSON or other delimited format, you can load them into a database, or extract the information for other uses. TextPipe translates the widest set of mainframe data, which can vary due to code pages, Cobol compiler dialect and mainframe host machine byte-ordering.
You can also use TextPipe to convert ASCII files to EBCDIC format.
|
|
Convert Mainframe Files Now |
Once you drag and drop your mainframe files into TextPipe, you choose which filters will be used to convert the file:
- Simple EBCDIC files with no structure. These can be converted using the Mainframe \ EBCDIC to ASCII filter.
- Fixed length mainframe files. Use the Mainframe \ EBCDIC to ASCII filter followed by the Convert \ End of Line Characters filter. For 132 column mainframe reports, set the fixed length to 133. To break the file down into fields/columns, just use the Fixed Width to Delimited Wizard.
- Mainframe CMS Format (variable line length files). Use the Convert \ End of Line Characters filter.
- Fixed record size (ie one segment) with a copybook (e.g. with packed and zoned decimals). Use the Mainframe Copybook filter and simply paste in your copybook. You can choose to output to CSV, Tab, XML, JSON, SQL Insert format, and using SQL Insert format, you can insert records directly into a database table.
- Multi-record (multiple segments) format. Use Mainframe\Mainframe copybook master record filter with multiple Mainframe\Mainframe copybook child record filters (see below) to split records into a different file for each record type. Output to CSV, Tab, XML, JSON, SQL Insert format, and using SQL Insert format, you can add a Database Filter to insert each record type into a different database table.
Sometimes TextPipe won't be able to parse your copybook - due to PIC clauses missing trailing periods, comments in the wrong spot, bizarre line breaks or field names etc. Please just send us the copybook or filter and we'll be happy to help.
When a Mainframe EBCDIC copybook consists of multiple records, you need to separate them out into a general structure, with each record type going to a new file for clarity and ease of loading/processing. TextPipe 11 makes this easy.
Sample Multi-Segment Mainframe EBCDIC Copybook
In our sample copybook below, the second field of every segment contains a 5 character record type id, T-REC_ID, which has values of #REC#, #TRAA, #TRAD etc. Fields beyond this are unique to each segment. Note: Often, the record type field's VALUES are not included in the copybook, but has to be read from the comments or documentation. In these cases the record type field usually has a constant name like REC-ID.
05 T-REC.
10 T-REC-LEN PIC S9(4) COMP VALUE 68.
10 T-REC-ID PIC X(5) VALUE '#REC#'.
10 T-REC-STAT PIC X VALUE 'N'.
...
05 T-TRAA.
10 T-TRAA-LEN PIC S9(4) COMP VALUE 69.
10 T-REC-ID PIC X(5) VALUE '#TRAA'.
10 T-TRAA-STAT PIC X VALUE 'N'.
...
05 T-TRAC.
10 T-TRAC-LEN PIC S9(4) COMP VALUE 68.
10 T-REC-ID PIC X(5) VALUE '#TRAC'.
10 T-TRAC-STAT PIC X VALUE 'N'.
...
05 T-TRAD.
10 T-TRAD-LEN PIC S9(4) COMP VALUE 199.
10 T-REC-ID PIC X(5) VALUE '#TRAD'.
10 T-TRAD-STAT PIC X VALUE 'N'.
...
Multi-segment COBOL copybook conversion
With TextPipe 11+ (download), the steps to convert a multi-segment cobol file are:
- Open TextPipe, and drag and drop your binary file that you want to convert (this file is in EBCDIC, not ASCII)
- From the Filters to Apply tab, Add a Filter Library\Mainframe\Mainframe copybook master record, and set the general options such as the output format (CSV, Tab, Pipe, XML, ;-delimited, JSON, SQL Insert script)
- Set the name of the field that contains the Record Type e.g. T-REC-ID, RECORD-TYPE. This field in each segment tells TextPipe which segment type is being processed
- Set the base output filename - this is the base folder and file that will be used for each segment. The name of the file will be base output filename plus the Segment Type
- Add one or more Filter Library\Mainframe\Mainframe copybook child record as subfilters (ie inside) the Mainframe copybook master record. You can drag child filters inside the master filter. These child filters inherit settings from their parent.
- In each child record), set the child record type (e.g. #REC#, #TRAA, #TRAD, A, B, C, 01, 02, 03) and paste in the associated copybook. If TextPipe complains about the format of your copybook, please contact support.
When a Mainframe EBCDIC copybook consists of multiple records, you need to separate them out into a general structure, with each record type going to a new file for clarity and ease of loading/processing. TextPipe makes this easy.
Here is how it looks:
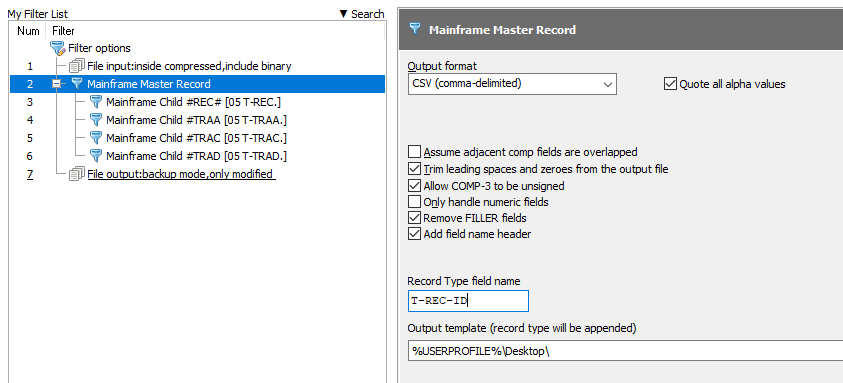
This results in the followings files being output
- User's Desktop\#REC#.csv - #REC# segments
- User's Desktop\#TRAA.csv - #TRAA segments
- User's Desktop\#TRAB.csv - #TRAB segments
- User's Desktop\#TRAC.csv - #TRAC segments
- User's Desktop\#TRAD.csv - #TRAD segments
|
|
Convert Mainframe Files Now |
Mainframe EBCDIC copybook filter design pattern
Sometimes the segment types can be a range of values, like 00-30, which could require a huge number of child records to be added. An alternative approach is available which allows you to use a pattern match to match the record type. With TextPipe (download), the steps are
- Use an EasyPattern match to identify each record type we have in the file – using the record header
- Pass this record header with its associated data to a subfilter
- The subfilter handles just that record type, and puts each record type in a new file.
In our sample file, each record starts with a 3 byte field which we will ignore, followed by a 5 letter record type id, #REC#, #TRAA, #TRAD etc. There is also a field following this record id, but we don't need it, and the value might not always be 'N'. Note: Often, the record type field's VALUES are not included in the copybook, but has to be read from the comments or documentation. In these cases the record type field usually has a constant name like REC-ID.
Sample Mainframe Copybook
05 T-REC.
10 T-REC-LEN PIC S9(4) COMP VALUE 68.
10 T-REC-ID PIC X(5) VALUE '#REC#'.
10 T-REC-STAT PIC X VALUE 'N'.
...
05 T-TRAA.
10 T-TRAA-LEN PIC S9(4) COMP VALUE 69.
10 T-TRAA-ID PIC X(5) VALUE '#TRAA'.
10 T-TRAA-STAT PIC X VALUE 'N'.
...
05 T-TRAC.
10 T-TRAC-LEN PIC S9(4) COMP VALUE 68.
10 T-TRAC-ID PIC X(5) VALUE '#TRAC'.
10 T-TRAC-STAT PIC X VALUE 'N'.
...
05 T-TRAD.
10 T-TRAD-LEN PIC S9(4) COMP VALUE 199.
10 T-TRAD-ID PIC X(5) VALUE '#TRAD'.
10 T-TRAD-STAT PIC X VALUE 'N'.
...
Records
The general TextPipe pattern for each record type within the file looks like this:

Let's dig into this.
The first step is an EasyPattern (a user-friendly type of pattern match). It looks for
- The start of the text, followed by
- Any 3 characters (the PIC S9(4) COMP field we are ignoring), followed by
- the EBCDIC characters #TRTS. (Remembering that PC's use ASCII, we need to specify the literal is EBCDIC), followed by
- 65 other characters – the rest of the record
When something matches this pattern, it must be a record of type #TRTS, and it gets passed unchanged to the subfilter:
- The Mainframe Copybook filter applies just the copybook segment that relates to the #TRTS record
- The result goes to the file TRTS-records.txt on your desktop
- The text is then prevented from continuing in the filter – it stops dead here.
Pro Tip: We can easily copy this structure by selecting the top filter, and choosing the [x2] button in the footer.
Working out the copybook size
When we paste each copybook fragment into a mainframe copybook filter, we can click the [Show Parse Tree] button to find out the record length. e.g.
-01 COPYBOOK 1-73 Length:73
05 T-TRAA 1-73 Length:73
10 T-TRAA-LEN S9(4) COMP-3. 1-3 Length:3
10 T-TRAA-ID X(5). 4-8 Length:5
10 T-TRAA-STAT X(1). 9 Length:1
10 T-TRAA-COMPL X(1). 10 Length:1
10 T-TRAA-COM S9(4) COMP-3. 11-13 Length:3
10 T-TRAA-DATA 14-73 Length:60
…
Once we know the length is 73, we just subtract 8 from it, (the first 3 characters followed by the 5 character record type = 8) to find out the remaining characters we need, in this case, 65:
[ TextStart, 3 chars, EBCDIC('#TRAA'),
65 chars ]
We also have to grab the record type TRAA from the copybook and put it into the pattern match, and also into the output filename.
%USERPROFILE%\Desktop\TRAA-Records.txt
Then we move onto the next record type.
Master record match
Once we have setup all the record types, we need to gather ALL the record patterns into one MASTER pattern match at the top of the list.
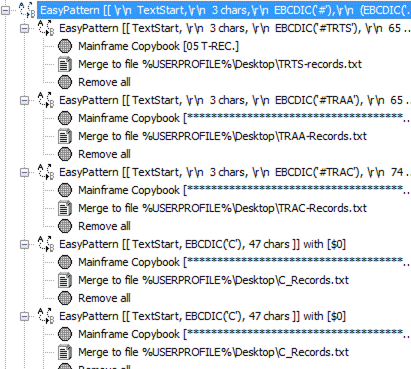
The master copybook pattern match looks like this:
[ TextStart,
3 chars,
EBCDIC('#'),
(EBCDIC('TRTS'), 65 chars)
or
(EBCDIC('TRAA'), 65 chars)
or
..one line for each record type..
(EBCDIC('TRTS'), 29 chars) ]
Ready to Rock 'n' Roll!
Then you're ready to drag and drop your mainframe file into TextPipe and click [Go] or press [F9]!
Errors?
If the error log reports that there were extra bytes in the file that could not be matched, this indicates that
- the pattern matches are incorrect
- the copybooks are incorrect. If you are converting a single record type, check that the file type is an exact multiple of the record size from the [Show Parse Tree] option. If you know you have just a single record type, you can use a website to get the prime factors of the file size to work out a likely copybook size.
- the settings used by the mainframe copybook filter are wrong. Try experimenting with the settings 'Assume adjacent COMP fields are overlapped' and 'Allow COMP-3 to be unsigned' of the most common or initial record type. Unfortunately the copybook does not tell us how exactly the data has been stored.
- the original data or original copybook is wrong
- the original data might have been converted to ASCII when it was transferred off the mainframe, and this is the most common problem we see. This leads to corrupted packed decimal values, so always ensure that the file you receive is FTPed off the mainframe in binary mode.
May the force be with you!
Automation
Once tested, the TextPipe filter can be run automatically or on a schedule from the command line. It can also be controlled by other software using COM.
Need Help With Your Copybook?
Please drop us an email with your copybook support@datamystic.com
|